
哪能搞法——动态规划再试
不知道有没有读者试过了这个大包包,我试了一下,在我的 2.30GHz i5 5300U 上,这个函数用 cPython 跑了…… 1632.07 秒,将近半个小时。照这个搞法,每次那个包有多大,就得搞出多少项。那个包的大小可是个任意数啊?这 $ W$ 比 $ 2^n$ 大都说不定呢?
咱们再来琢磨琢磨这个事儿。看看刚才那个最小的例子,也就是背包总重不超过 16,有这样几件物品:
| 物品 | 价值 | 重量 |
|---|---|---|
| 0 | 30 | 4 |
| 1 | 20 | 5 |
| 2 | 40 | 10 |
| 3 | 10 | 3 |
我们产生的 $ F$ 是这样的:
[0, 0, 0, 0, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30] [0, 0, 0, 0, 30, 30, 30, 30, 30, 50, 50, 50, 50, 50, 50, 50, 50] [0, 0, 0, 0, 30, 30, 30, 30, 30, 50, 50, 50, 50, 50, 70, 70, 70] [0, 0, 0, 10, 30, 30, 30, 40, 40, 50, 50, 50, 60, 60, 70, 70, 70]
你什么感觉,是不是怎么这么多重复项??我们真的需要保留这么多重复项吗?
动态规划说到底,是把 $ n$ 个对象的情况化归成 $ n-x$ 个对象的子问题。我们这个 $ F$ 里面实际的信息量是什么呢?
- 第一轮,加入 0 号物品,可以用 4 的重量做到 30 的价值。
- 第二轮,加入 1 号物品,可以用 5 的重量做到 20 的价值——慢着,我们前一轮已经用 4 的重量做到的 30 的价值,你用 5 才做到 20,这完全没有意义嘛!所以它并没有表现在 $ F$ 中。然而如果同时加入 0 号和 1 号物品,我们就可以用 9 的重量做到 50 的价值。这是一个新的信息。
- 第三轮,再加入 2 号物品,同理,我们只有在重量达到 14,价值达到 70 的时候才是一个新的信息。
- 第四轮,我们用 3 的重量就做到了 10 的价值,而以前 3 的重量什么也做不出。那么这也是一个新信息。
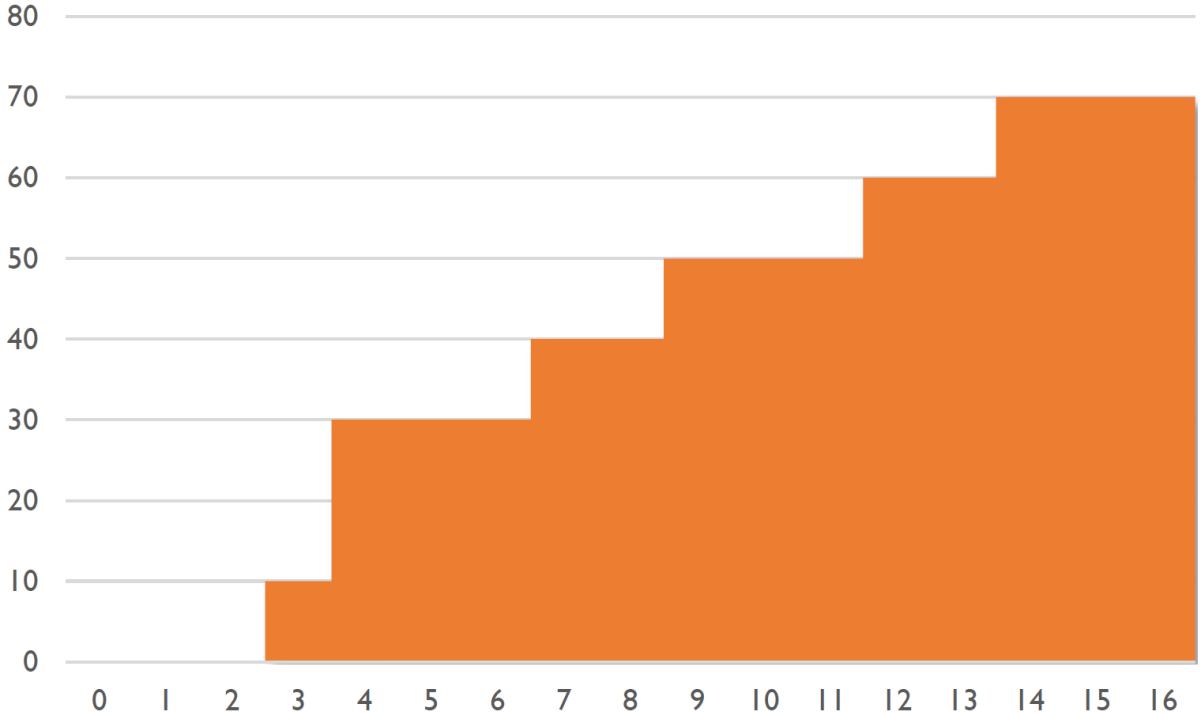
看出什么端倪了么?我们其实只需要保留有信息量的部分,即用最少的重量做到某一个价值的时刻。如果有两个状态 $ (V_1, W_1)$ 和 $ (V_2, W_2)$,使得 $ W_2 > W_1$,但 $V_2 \leq V_1$,也就是说状态 2 的重量大但价值不高的话,那么就说明状态 2 是占劣势而无需继续考虑的。如果能把这些劣势状态通通舍弃,我们要处理的数据量(通常)可以大大缩减。
道理理解了,如何实现呢?我们可以用元组 (tuple) 来表示价值和重量,并把它们按顺序排起来。仍以上面的例子来说:
- 最初我们什么也没有,只有一个元组
(0, 0) - 我们试着加上第 0 号元素,得到了
(30, 4)。与最初的元组合并,于是变成了(0, 0), (30, 4)。 - 再试着对每一种情况加上第 1 号元素,得到了
(20, 5), (50, 9)。与上一轮的元组合并,由于(20, 5)处于劣势被舍弃了。合并的结果是(0, 0), (30, 4), (50, 9)。 - 继续做这个操作,加上第 2 号元素得到
(40, 10), (70, 14), (90, 19)。最后一个由于超限被舍弃了,再于上一轮合并,得到(0, 0), (30, 4), (50, 9), (70, 14)。 - 最后一轮再加上去,终于得到了最终结果
(0, 0), (10, 3), (30, 4), (40, 7), (50, 9), (60, 12), (70, 14)。
我的这个实现为了合并的方便使用了 python 中的双向链表 collections.deque。它不但写起来方便,而且实测下来比直接用列表和指针还要快一些(原因未知):
#!/usr/bin/env python3
from collections import deque
import sys
INF = float("inf")
def knapsack(vw, limit, n):
vw = sorted(vw, key=lambda x : x[1], reverse=True) # Accelerate
A = deque([(0, 0)])
for i in range(0, n):
B = deque() # find all possiblities after adding one new item
for item in A:
if item[1] + vw[i][1] > limit: # A is sorted
break
B.append((item[0] + vw[i][0], item[1] + vw[i][1]))
level, merge = -1, deque() # the bar keeps going up
while A or B: # merging the two queues
ia, ib = A[0][1] if A else INF, B[0][1] if B else INF
x = A.popleft() if (ia < ib) else B.popleft()
if x[0] > level:
merge.append(x)
level = x[0]
A = merge
return A[-1]
if __name__ == "__main__":
with open(sys.argv[1] if len(sys.argv) > 1 else sys.exit(1)) as f:
limit, n = map(int, f.readline().split())
vw = [tuple(map(int, ln.split())) for ln in f.readlines()]
A = knapsack(vw, limit, n)
print("Max value:", A[0], "Total weight:", A[1])
用这个来解决大包包是轻轻松松啦!在我机器上的运行时间大约只有半秒钟,真的可谓是秒杀!我们这个算法的时间复杂度是 $O(ns)$,其中 $s$ 是上面列出来的独立状态数。这个状态数既不可能超过 $W$,也不可能超过 $2^n$。对于分布比较均匀的背包物品来说,这个方法还是相当奏效的。
也许你注意到了第 8 行有一条奇怪的排序……这个算法虽然对数据的顺序本身没有要求,但是我发现,如果对数据按照重量从大到小排序,速度比乱序提升了大约四倍。我也试过其他的排序方法,比如按照价值与重量的比值,但在这个特定例子上均不太理想。
但是呢……遇到更大的包包怎么办……我跑了一下 cPython 需要 677.3 秒…… PyPy 快一些需要 65 秒左右。
其实,我们并不需要在动态规划这一棵树上吊死的呢…… 且听下回分解。
更多算法内容请见《算法拾珠》。
这种情况怎么回溯输出解决方案呢